🔥
Kontrakting
Sprawdź nowy moduł zarządzania kontraktorami
🔥
Kontrakting
Sprawdź nowy moduł zarządzania kontraktorami
🔥
Kontrakting
Sprawdź nowy moduł zarządzania kontraktorami
🔥
Kontrakting
Sprawdź nowy moduł zarządzania kontraktorami
Zaktualizowano:
CV Parser: Kiedy CV zaczyna pracować jako dane

Nowości

Iwo Paliszewski
CV Parser: Kiedy CV zaczyna pracować jako dane
Dla wielu zespołów rekrutacyjnych CV wciąż traktowane jest głównie jako dokument.
Coś, co można otworzyć, przeczytać, ocenić, pobrać, przesłać dalej, porównać i zarchiwizować. Często jest to punkt startowy procesu rekrutacji, ale zazwyczaj na tym jego rola się kończy: pozostaje po prostu plikiem podpiętym pod profil kandydata.
Problem w tym, że zespoły rekrutacyjne nie potrzebują wyłącznie dokumentów. Potrzebują użytecznych informacji.
Muszą wiedzieć, jakie umiejętności posiada kandydat, gdzie pracował, jakie firmy widnieją w jego historii, jakie zajmował stanowiska, jakim posługuje się językiem i gdzie się znajduje. A co najważniejsze – jak to wszystko bezproblemowo przeszukiwać, filtrować, łączyć i wykorzystywać w przyszłości.
Właśnie dlatego postrzegamy parsowanie CV jako coś znacznie ważniejszego niż tylko „szybsze wgrywanie życiorysu”.
Dobry parser CV nie powinien służyć jedynie do oszczędzania czasu na ręcznym przepisywaniu danych. Powinien pomagać w zamianie statycznego dokumentu w ustrukturyzowane dane rekrutacyjne. A kiedy CV staje się zbiorem danych, zaczyna realnie pracować na korzyść rekrutera.
CV to znacznie więcej niż tylko dane kontaktowe
Kiedy myślimy o parsowaniu CV, zazwyczaj przychodzą nam do głowy absolutne podstawy: imię i nazwisko, adres e-mail, numer telefonu, stanowisko, wykształcenie i doświadczenie zawodowe.
Oczywiście, to bardzo przydatne. Nikt nie chce ręcznie przeklejać informacji z PDF-a, jeśli system może to zrobić automatycznie. Jednak w rekrutacji prawdziwa wartość CV wykracza daleko poza same dane kontaktowe.
CV to kompletna historia zawodowa. Kryją się w niej firmy, branże, ścieżki kariery, umiejętności, poziom seniority, technologie, języki obce, lokalizacje i mnóstwo pośredniego kontekstu, który może okazać się kluczowy w przyszłości.
Na przykład: jeśli kandydat pracował dla trzech różnych software house'ów, to wysyła nam to konkretny sygnał. Jeśli przeszedł z agencji rekrutacyjnej do wewnętrznego HR-u – to również ma znaczenie. Znaczenie ma też to, czy spędził lata w finansach, ochronie zdrowia, logistyce czy produkcji. Jego lokalizacja jest kluczowa, zwłaszcza gdy rekrutujemy do ról hybrydowych, lokalnych, w pełni zdalnych lub wymagających relokacji.
CV to nie tylko dokument. To mapa profesjonalnych doświadczeń, relacji i rynkowego kontekstu.
Wyzwaniem jest to, że ta mapa zazwyczaj ukryta jest w nieustrukturyzowanym tekście. Dopóki system nie potrafi jej wydobyć, uporządkować i połączyć z resztą bazy danych, większość tej wartości pozostaje uwięziona w pliku.
Ręczne wprowadzanie danych generuje tarcia i niespójności
Rekruterzy zazwyczaj świetnie radzą sobie ze zrozumieniem CV. Problemem nie jest ludzka interpretacja. Problemem jest powtarzalność.
Kiedy rekruter musi ręcznie utworzyć profil kandydata, skopiować dane, dodać historię zatrudnienia, wyłuskać umiejętności, wpisać nazwy firm, dodać lokalizację i odpowiednio to ustrukturyzować – proces staje się wolniejszy i o wiele bardziej niespójny.
Jeden rekruter wpisze „JavaScript”, inny „JS”. Ktoś doda „angielski” jako język, a ktoś inny to pominie, bo w danej roli nie było to wymagane. Jeden rekruter doda Warszawę jako lokalizację, drugi zostawi to pole puste. Ktoś utworzy pełen profil firmy dla poprzedniego pracodawcy, inny zostawi jego nazwę jedynie jako ciąg znaków w notatce.
Pojedynczo te wybory wydają się błahe. Ale z czasem to one kształtują jakość bazy danych.
A jakość bazy ma fundamentalne znaczenie. Wpływa na wyszukiwanie, raportowanie, budowanie pul talentów, direct search, matchowanie kandydatów i możliwość ich ponownego wykorzystania. Jeśli informacje nie zostaną dobrze ustrukturyzowane na samym początku, system bardzo szybko przestaje wzbudzać zaufanie.
Dlatego parsowanie to nie tylko kwestia szybkości. To kwestia spójności danych.
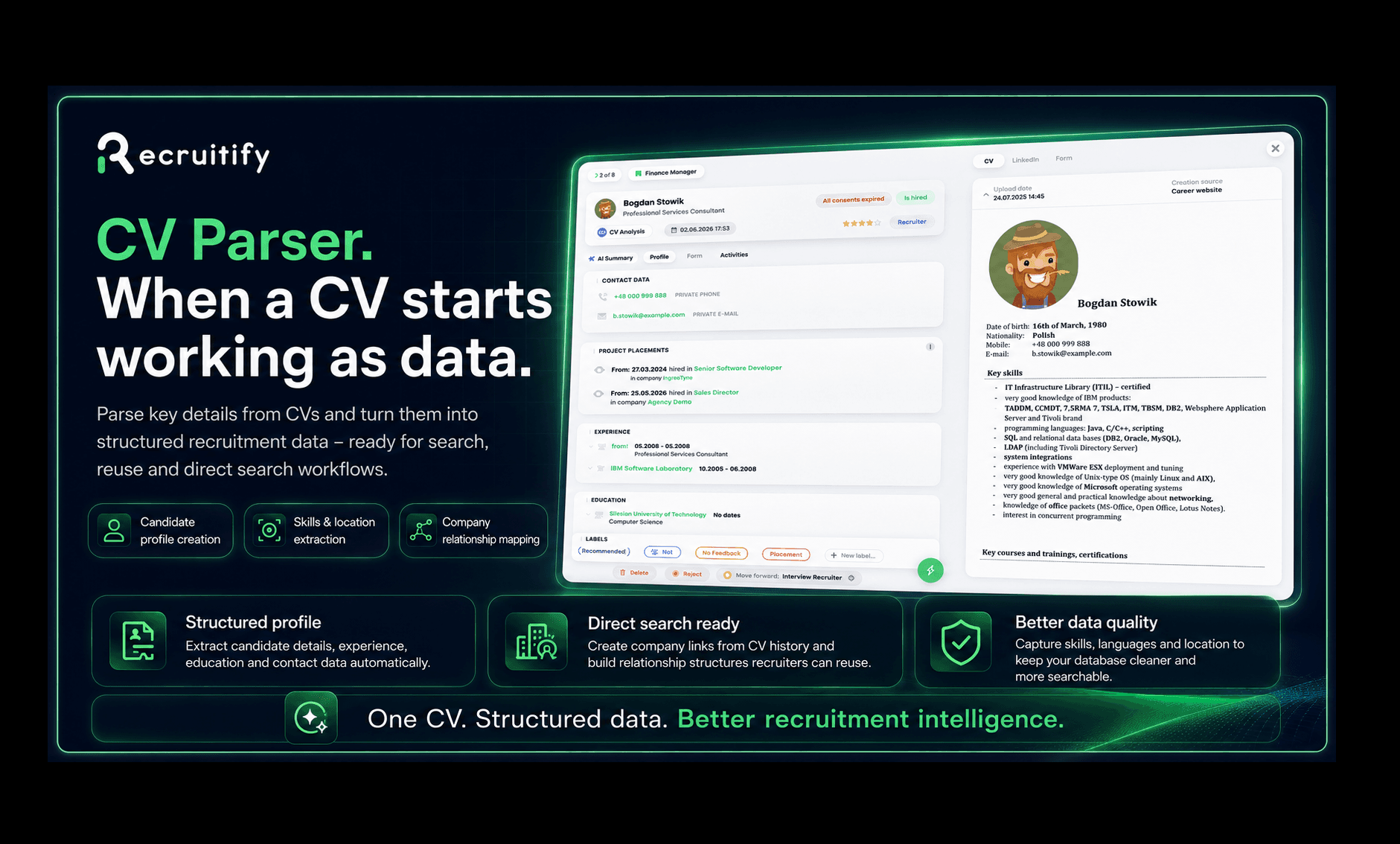
Od pliku CV do pełnoprawnego profilu kandydata
Główny cel CV Parsera w Recruitify jest prosty: pomóc rekruterom w tworzeniu profili kandydatów szybciej i przy minimalnym nakładzie pracy ręcznej.
Po wgraniu życiorysu system wyciąga kluczowe informacje i buduje na ich podstawie gotowy profil. Obejmuje to podstawowe dane, doświadczenie, wykształcenie, umiejętności, języki, lokalizację i wszelkie inne istotne szczegóły, które można od razu wykorzystać w procesie rekrutacji.
Ma to potężne znaczenie, ponieważ pierwsze kilka minut pracy z kandydatem często decyduje o tym, czy baza będzie użyteczna w przyszłości.
Jeśli profil jest niekompletny, trudny do znalezienia, brakuje w nim kluczowych umiejętności lub lokalizacji, rekruter nadal poprowadzi bieżący proces, ale kandydat traci na wartości w kontekście przyszłych projektów. Dobrze sparsowany profil ułatwia znalezienie, porównanie, zakwalifikowanie i powrót do kandydata przy kolejnych poszukiwaniach.
CV przestaje być tylko załącznikiem. Staje się integralną częścią systemu rekrutacyjnego.
Dane o lokalizacji pomagają uporządkować bazę
Lokalizacja to jeden z tych detali, które wydają się prozaiczne, ale w rekrutacji potrafią zrobić kolosalną różnicę.
Wiele poszukiwań nadal dyktuje geografia. Nawet w erze pracy zdalnej, liczne role mają charakter hybrydowy, regionalny, są przypisane do konkretnego klienta, kraju, biura lub strefy czasowej. Ze względów prawnych, płacowych lub językowych – lokalizacja wciąż ma ogromne znaczenie.
Jeśli lokalizacja kandydata jest ukryta wyłącznie w tekście CV, rekruterzy mogą ją łatwo przeoczyć podczas przyszłych wyszukiwań. Jeśli jednak jest ustrukturyzowana w profilu – filtrowanie bazy staje się banalnie proste.
Właśnie dlatego ekstrakcja lokalizacji jest tak ważna. Parser, który pomaga przypisać właściwe miejsce zamieszkania do profilu, dba o lepszą organizację całej bazy. Czyni ją czystszą i bardziej użyteczną dla przyszłych ról. Pozwala też uniknąć niepotrzebnego ręcznego przeglądania dziesiątek profili, gdy zespół na cito potrzebuje kandydata z konkretnego regionu.
I znów – tu nie chodzi o wypełnienie kolejnego okienka w systemie. Chodzi o to, by dane kandydata były w pełni gotowe do użycia.
Budowanie bazy firm na podstawie CV kandydatów
Jednym z obszarów, na którym szczególnie zależało nam w Recruitify, są relacje między kandydatami a firmami.
W wielu systemach rekrutacyjnych firmy istnieją tylko wtedy, gdy ktoś z zespołu ręcznie doda je jako klientów lub pracodawców. A przecież CV kandydatów są wręcz naszpikowane informacjami o organizacjach biznesowych. Historia zatrudnienia ujawnia, gdzie kandydat pracował, jakie firmy liczą się na danym rynku talentów i jak płynnie ludzie przemieszczają się między pracodawcami.
To dlatego nasz parser potrafi również tworzyć rekordy firm bezpośrednio z życiorysów kandydatów.
Jeśli CV kandydata wymienia poprzednich pracodawców, system automatycznie wyciąga ich nazwy, pomagając utworzyć lub połączyć je wewnątrz bazy danych. Kandydat zostaje trwale powiązany z tymi organizacjami jako ich obecny lub były pracownik.
Może to brzmieć jak drobny techniczny detal, ale dla zespołów rekrutacyjnych – zwłaszcza agencji i headhunterów – jest to funkcjonalność na wagę złota. Bo rekrutacja to nie tylko analizowanie pojedynczych kandydatów. To głębokie zrozumienie całego rynku.
Budowanie struktur powiązań dla Direct Search
Direct search mocno opiera się na kontekście. Rekruterzy chcą wiedzieć nie tylko kim jest kandydat, ale gdzie pracował, które firmy „produkują” określone typy talentów, które organizacje mają znaczenie w danym sektorze i jak kandydaci są ze sobą powiązani.
Gdy system tworzy struktury firm z CV i od razu łączy z nimi kandydatów, baza danych staje się czymś więcej niż tylko listą profili. Zaczyna przekształcać się w mapę powiązań rynkowych.
To nieoceniona przewaga, gdy rekruterzy pracują nad podobnymi rolami, mapują konkurencję, budują wywiad rynkowy lub szukają talentów z doświadczeniem w specyficznym środowisku biznesowym.
Dla przykładu: rekruter może chcieć znaleźć osoby, które pracowały w określonych firmach technologicznych, consultingowych, medycznych czy produkcyjnych. Jeśli ta informacja żyje tylko w pliku PDF, jest praktycznie bezużyteczna. Jeśli jest zmapowana w systemie – staje się łatwa do wyszukania.
A to całkowicie zmienia wartość całej bazy danych.
Ekstrakcja umiejętności zamienia doświadczenie w wyszukiwalne sygnały
Umiejętności (skills) to jedna z najważniejszych składowych danych rekrutacyjnych, ale jednocześnie obszar, który najłatwiej zepsuć złym tagowaniem.
Kandydaci opisują swoje kompetencje w najróżniejszy sposób. Różnią się formaty dokumentów. Jedni mają świetnie wypunktowane listy technologii. Inni przemycają je w rozwlekłych opisach stanowisk. Niektórzy używają skrótów, inni pełnych nazw.
Parser pomaga wyłuskać te umiejętności i zunifikować je jako użyteczne tagi wewnątrz systemu.
To kluczowe dla zaawansowanego wyszukiwania, budowy Puli Talentów (Talent Pools), raportowania i przyszłych projektów. Jeśli umiejętności zostaną odpowiednio wychwycone, rekruterzy mogą wrócić do bazy i błyskawicznie odnaleźć pasujących ludzi, zamiast za każdym razem zaczynać od zewnętrznego sourcingu.
Ale to nie jest po prostu dodanie większej liczby słów kluczowych. To tworzenie ustrukturyzowanych sygnałów.
Gdy połączymy kompetencje, doświadczenie, firmy, języki, lokalizacje i historię, baza zyskuje potężną moc. Rekruterzy mogą wyszukiwać dane z większą pewnością, skuteczniej segmentować kandydatów i identyfikować ludzi, którzy w przeciwnym razie na zawsze zniknęliby w czeluściach starych plików.
Lepsze dane to lepsze ponowne wykorzystanie (Reuse)
Baza rekrutacyjna jest wartościowa dopiero wtedy, gdy można ją użyć ponownie. Nie tylko przy okazji jednego, bieżącego projektu, ale przy przyszłych wakatach, u różnych klientów, przy zasilaniu pul talentów i budowaniu wieloletnich relacji z kandydatem.
To właśnie w takich momentach ustrukturyzowane dane z CV okazują się krytyczne. Jeśli parser wydobędzie szczegóły z dokumentu, rekruter może na ich podstawie tworzyć Dynamiczne Pule Talentów, odpalać zaawansowane wyszukiwania i identyfikować świetne profile z poprzednich procesów.
Bez ustrukturyzowanych danych kandydat nadal tkwi w systemie, ale wyciągnięcie go na powierzchnię jest niezwykle uciążliwe. A kandydat, którego nie da się znaleźć w odpowiednim momencie, jest warty dokładnie tyle samo, co kandydat, którego w ogóle w bazie nie ma.
To jeden z powodów, dla których uważamy, że parsowanie powinno być traktowane przede wszystkim jako narzędzie do dbania o jakość danych, a dopiero w drugiej kolejności jako narzędzie ułatwiające pracę.
Parser dba o przyszłość Twojej bazy
Kształt każdej bazy rekrutacyjnej zależy od tego, w jaki sposób wprowadzane są do niej dane.
Jeśli proces ten przebiega ręcznie, niespójnie lub powierzchownie, system powoli staje się niezdatny do użytku. Z biegiem czasu rekruterzy po prostu tracą do niego zaufanie. Wracają na LinkedIna i inwestują w nowe ogłoszenia, bo wewnętrzna wyszukiwarka wydaje się nieprzewidywalna.
Dobry parser pomaga temu zapobiec już na samym starcie.
Tworzy mocny fundament pod profil kandydata, relacje firmowe, wyszukiwanie po lokalizacji, skille, przyszłe automatyzacje i ponowne wykorzystanie bazy. Pomaga utrzymać użyteczność systemu nie tylko dziś, ale także za wiele miesięcy i lat.
Oczywiście, to nie oznacza, że każdy profil będzie nieskazitelny. Formaty życiorysów są nieszablonowe. Informacje nie zawsze są kompletne. Ludzka weryfikacja wciąż odgrywa istotną rolę. Ale celem wcale nie jest wykluczenie rekrutera z tego procesu. Celem jest wyeliminowanie niepotrzebnej, powtarzalnej „dłubaniny” i stworzenie znacznie lepszego punktu wyjścia.
Parsowanie CV to nie tylko uciążliwa administracja
Bardzo łatwo jest bagatelizować wdrożenie CV Parsera, bo brzmi to mocno operacyjnie. Wgraj CV. Wyciągnij dane. Utwórz profil.
W rzeczywistości proces ten dotyka czegoś o wiele większego: jakości samego systemu rekrutacyjnego.
Jeśli dane kandydatów są słabe, wyszukiwanie staje się uciążliwe.
Jeśli brakuje powiązań z firmami, mapowanie rynku kuleje.
Jeśli umiejętności nie zostały zunifikowane, matchowanie kandydatów zawodzi.
Jeśli brakuje lokalizacji, filtry stają się bezużyteczne.
Jeśli profile są dziurawe, Pule Talentów tracą na wartości.
Jeśli baza nie budzi zaufania – zespół znów musi zaczynać od nowa.
Właśnie dlatego CV Parser w Recruitify to nie tylko narzędzie do oszczędzenia kilku minut podczas dodawania aplikacji. To mechanizm, który dba o to, by bezcenne informacje z życiorysu nie utknęły w martwym dokumencie, lecz stały się w pełni ustrukturyzowane, wyszukiwalne i powiązane z całym ekosystemem.
Dlaczego zaprojektowaliśmy to w ten sposób
Zbudowaliśmy nasz CV Parser właśnie tak, ponieważ wiemy, że zespoły rekrutacyjne już teraz posiadają znacznie więcej informacji, niż same zdają sobie sprawę. Problemem jest to, że lwią część z nich ukryto po plikach, w notatkach i rozrzuconych skrzynkach mailowych.
CV nie powinno być martwym załącznikiem w systemie. Powinno aktywnie współtworzyć profil kandydata, wzbogacać bazę danych, budować biznesowy kontekst firmowy, wspierać direct search, porządkować kompetencje oraz lokalizacje, i realnie ułatwiać pracę rekruterom w przyszłości.
Bo dane rekrutacyjne mają wartość tylko wtedy, gdy można ich w każdej chwili użyć. A w momencie, w którym CV zaczyna pracować jako dane, cały proces rekrutacyjny staje się niesamowicie połączoną, zintegrowaną całością.
Taka właśnie idea przyświecała nam podczas tworzenia CV Parsera w Recruitify: to nie tylko szybsze założenie nowej karty profilowej. To budowanie inteligentnej analityki rekrutacyjnej już od pierwszego kliknięcia myszką.


Aktualizacje i nowości
Bądź na bieżąco z najnowszymi innowacjami, funkcjami i wskazówkami dotyczącymi Recruitify!
Podając swój adres e-mail w ramach formularza zapisu na newsletter wyrażasz zgodę na jego przetwarzanie w celu przesyłania informacji marketingowych dotyczących produktów i usług Administratora. Administratorem Twoich danych osobowych przetwarzanych w powyższym celu jest Recruitify Sp. z o.o. z siedzibą w Warszawie (KRS 0000709889). Więcej informacji na temat zasad przetwarzania danych osobowych i praw osób, których dane dotyczą znajdziesz w dokumencie Polityka prywatności.

Zaktualizowano:
CV Parser: Kiedy CV zaczyna pracować jako dane
Nowości
Iwo Paliszewski
CV Parser: Kiedy CV zaczyna pracować jako dane
Dla wielu zespołów rekrutacyjnych CV wciąż traktowane jest głównie jako dokument.
Coś, co można otworzyć, przeczytać, ocenić, pobrać, przesłać dalej, porównać i zarchiwizować. Często jest to punkt startowy procesu rekrutacji, ale zazwyczaj na tym jego rola się kończy: pozostaje po prostu plikiem podpiętym pod profil kandydata.
Problem w tym, że zespoły rekrutacyjne nie potrzebują wyłącznie dokumentów. Potrzebują użytecznych informacji.
Muszą wiedzieć, jakie umiejętności posiada kandydat, gdzie pracował, jakie firmy widnieją w jego historii, jakie zajmował stanowiska, jakim posługuje się językiem i gdzie się znajduje. A co najważniejsze – jak to wszystko bezproblemowo przeszukiwać, filtrować, łączyć i wykorzystywać w przyszłości.
Właśnie dlatego postrzegamy parsowanie CV jako coś znacznie ważniejszego niż tylko „szybsze wgrywanie życiorysu”.
Dobry parser CV nie powinien służyć jedynie do oszczędzania czasu na ręcznym przepisywaniu danych. Powinien pomagać w zamianie statycznego dokumentu w ustrukturyzowane dane rekrutacyjne. A kiedy CV staje się zbiorem danych, zaczyna realnie pracować na korzyść rekrutera.
CV to znacznie więcej niż tylko dane kontaktowe
Kiedy myślimy o parsowaniu CV, zazwyczaj przychodzą nam do głowy absolutne podstawy: imię i nazwisko, adres e-mail, numer telefonu, stanowisko, wykształcenie i doświadczenie zawodowe.
Oczywiście, to bardzo przydatne. Nikt nie chce ręcznie przeklejać informacji z PDF-a, jeśli system może to zrobić automatycznie. Jednak w rekrutacji prawdziwa wartość CV wykracza daleko poza same dane kontaktowe.
CV to kompletna historia zawodowa. Kryją się w niej firmy, branże, ścieżki kariery, umiejętności, poziom seniority, technologie, języki obce, lokalizacje i mnóstwo pośredniego kontekstu, który może okazać się kluczowy w przyszłości.
Na przykład: jeśli kandydat pracował dla trzech różnych software house'ów, to wysyła nam to konkretny sygnał. Jeśli przeszedł z agencji rekrutacyjnej do wewnętrznego HR-u – to również ma znaczenie. Znaczenie ma też to, czy spędził lata w finansach, ochronie zdrowia, logistyce czy produkcji. Jego lokalizacja jest kluczowa, zwłaszcza gdy rekrutujemy do ról hybrydowych, lokalnych, w pełni zdalnych lub wymagających relokacji.
CV to nie tylko dokument. To mapa profesjonalnych doświadczeń, relacji i rynkowego kontekstu.
Wyzwaniem jest to, że ta mapa zazwyczaj ukryta jest w nieustrukturyzowanym tekście. Dopóki system nie potrafi jej wydobyć, uporządkować i połączyć z resztą bazy danych, większość tej wartości pozostaje uwięziona w pliku.
Ręczne wprowadzanie danych generuje tarcia i niespójności
Rekruterzy zazwyczaj świetnie radzą sobie ze zrozumieniem CV. Problemem nie jest ludzka interpretacja. Problemem jest powtarzalność.
Kiedy rekruter musi ręcznie utworzyć profil kandydata, skopiować dane, dodać historię zatrudnienia, wyłuskać umiejętności, wpisać nazwy firm, dodać lokalizację i odpowiednio to ustrukturyzować – proces staje się wolniejszy i o wiele bardziej niespójny.
Jeden rekruter wpisze „JavaScript”, inny „JS”. Ktoś doda „angielski” jako język, a ktoś inny to pominie, bo w danej roli nie było to wymagane. Jeden rekruter doda Warszawę jako lokalizację, drugi zostawi to pole puste. Ktoś utworzy pełen profil firmy dla poprzedniego pracodawcy, inny zostawi jego nazwę jedynie jako ciąg znaków w notatce.
Pojedynczo te wybory wydają się błahe. Ale z czasem to one kształtują jakość bazy danych.
A jakość bazy ma fundamentalne znaczenie. Wpływa na wyszukiwanie, raportowanie, budowanie pul talentów, direct search, matchowanie kandydatów i możliwość ich ponownego wykorzystania. Jeśli informacje nie zostaną dobrze ustrukturyzowane na samym początku, system bardzo szybko przestaje wzbudzać zaufanie.
Dlatego parsowanie to nie tylko kwestia szybkości. To kwestia spójności danych.
Od pliku CV do pełnoprawnego profilu kandydata
Główny cel CV Parsera w Recruitify jest prosty: pomóc rekruterom w tworzeniu profili kandydatów szybciej i przy minimalnym nakładzie pracy ręcznej.
Po wgraniu życiorysu system wyciąga kluczowe informacje i buduje na ich podstawie gotowy profil. Obejmuje to podstawowe dane, doświadczenie, wykształcenie, umiejętności, języki, lokalizację i wszelkie inne istotne szczegóły, które można od razu wykorzystać w procesie rekrutacji.
Ma to potężne znaczenie, ponieważ pierwsze kilka minut pracy z kandydatem często decyduje o tym, czy baza będzie użyteczna w przyszłości.
Jeśli profil jest niekompletny, trudny do znalezienia, brakuje w nim kluczowych umiejętności lub lokalizacji, rekruter nadal poprowadzi bieżący proces, ale kandydat traci na wartości w kontekście przyszłych projektów. Dobrze sparsowany profil ułatwia znalezienie, porównanie, zakwalifikowanie i powrót do kandydata przy kolejnych poszukiwaniach.
CV przestaje być tylko załącznikiem. Staje się integralną częścią systemu rekrutacyjnego.
Dane o lokalizacji pomagają uporządkować bazę
Lokalizacja to jeden z tych detali, które wydają się prozaiczne, ale w rekrutacji potrafią zrobić kolosalną różnicę.
Wiele poszukiwań nadal dyktuje geografia. Nawet w erze pracy zdalnej, liczne role mają charakter hybrydowy, regionalny, są przypisane do konkretnego klienta, kraju, biura lub strefy czasowej. Ze względów prawnych, płacowych lub językowych – lokalizacja wciąż ma ogromne znaczenie.
Jeśli lokalizacja kandydata jest ukryta wyłącznie w tekście CV, rekruterzy mogą ją łatwo przeoczyć podczas przyszłych wyszukiwań. Jeśli jednak jest ustrukturyzowana w profilu – filtrowanie bazy staje się banalnie proste.
Właśnie dlatego ekstrakcja lokalizacji jest tak ważna. Parser, który pomaga przypisać właściwe miejsce zamieszkania do profilu, dba o lepszą organizację całej bazy. Czyni ją czystszą i bardziej użyteczną dla przyszłych ról. Pozwala też uniknąć niepotrzebnego ręcznego przeglądania dziesiątek profili, gdy zespół na cito potrzebuje kandydata z konkretnego regionu.
I znów – tu nie chodzi o wypełnienie kolejnego okienka w systemie. Chodzi o to, by dane kandydata były w pełni gotowe do użycia.
Budowanie bazy firm na podstawie CV kandydatów
Jednym z obszarów, na którym szczególnie zależało nam w Recruitify, są relacje między kandydatami a firmami.
W wielu systemach rekrutacyjnych firmy istnieją tylko wtedy, gdy ktoś z zespołu ręcznie doda je jako klientów lub pracodawców. A przecież CV kandydatów są wręcz naszpikowane informacjami o organizacjach biznesowych. Historia zatrudnienia ujawnia, gdzie kandydat pracował, jakie firmy liczą się na danym rynku talentów i jak płynnie ludzie przemieszczają się między pracodawcami.
To dlatego nasz parser potrafi również tworzyć rekordy firm bezpośrednio z życiorysów kandydatów.
Jeśli CV kandydata wymienia poprzednich pracodawców, system automatycznie wyciąga ich nazwy, pomagając utworzyć lub połączyć je wewnątrz bazy danych. Kandydat zostaje trwale powiązany z tymi organizacjami jako ich obecny lub były pracownik.
Może to brzmieć jak drobny techniczny detal, ale dla zespołów rekrutacyjnych – zwłaszcza agencji i headhunterów – jest to funkcjonalność na wagę złota. Bo rekrutacja to nie tylko analizowanie pojedynczych kandydatów. To głębokie zrozumienie całego rynku.
Budowanie struktur powiązań dla Direct Search
Direct search mocno opiera się na kontekście. Rekruterzy chcą wiedzieć nie tylko kim jest kandydat, ale gdzie pracował, które firmy „produkują” określone typy talentów, które organizacje mają znaczenie w danym sektorze i jak kandydaci są ze sobą powiązani.
Gdy system tworzy struktury firm z CV i od razu łączy z nimi kandydatów, baza danych staje się czymś więcej niż tylko listą profili. Zaczyna przekształcać się w mapę powiązań rynkowych.
To nieoceniona przewaga, gdy rekruterzy pracują nad podobnymi rolami, mapują konkurencję, budują wywiad rynkowy lub szukają talentów z doświadczeniem w specyficznym środowisku biznesowym.
Dla przykładu: rekruter może chcieć znaleźć osoby, które pracowały w określonych firmach technologicznych, consultingowych, medycznych czy produkcyjnych. Jeśli ta informacja żyje tylko w pliku PDF, jest praktycznie bezużyteczna. Jeśli jest zmapowana w systemie – staje się łatwa do wyszukania.
A to całkowicie zmienia wartość całej bazy danych.
Ekstrakcja umiejętności zamienia doświadczenie w wyszukiwalne sygnały
Umiejętności (skills) to jedna z najważniejszych składowych danych rekrutacyjnych, ale jednocześnie obszar, który najłatwiej zepsuć złym tagowaniem.
Kandydaci opisują swoje kompetencje w najróżniejszy sposób. Różnią się formaty dokumentów. Jedni mają świetnie wypunktowane listy technologii. Inni przemycają je w rozwlekłych opisach stanowisk. Niektórzy używają skrótów, inni pełnych nazw.
Parser pomaga wyłuskać te umiejętności i zunifikować je jako użyteczne tagi wewnątrz systemu.
To kluczowe dla zaawansowanego wyszukiwania, budowy Puli Talentów (Talent Pools), raportowania i przyszłych projektów. Jeśli umiejętności zostaną odpowiednio wychwycone, rekruterzy mogą wrócić do bazy i błyskawicznie odnaleźć pasujących ludzi, zamiast za każdym razem zaczynać od zewnętrznego sourcingu.
Ale to nie jest po prostu dodanie większej liczby słów kluczowych. To tworzenie ustrukturyzowanych sygnałów.
Gdy połączymy kompetencje, doświadczenie, firmy, języki, lokalizacje i historię, baza zyskuje potężną moc. Rekruterzy mogą wyszukiwać dane z większą pewnością, skuteczniej segmentować kandydatów i identyfikować ludzi, którzy w przeciwnym razie na zawsze zniknęliby w czeluściach starych plików.
Lepsze dane to lepsze ponowne wykorzystanie (Reuse)
Baza rekrutacyjna jest wartościowa dopiero wtedy, gdy można ją użyć ponownie. Nie tylko przy okazji jednego, bieżącego projektu, ale przy przyszłych wakatach, u różnych klientów, przy zasilaniu pul talentów i budowaniu wieloletnich relacji z kandydatem.
To właśnie w takich momentach ustrukturyzowane dane z CV okazują się krytyczne. Jeśli parser wydobędzie szczegóły z dokumentu, rekruter może na ich podstawie tworzyć Dynamiczne Pule Talentów, odpalać zaawansowane wyszukiwania i identyfikować świetne profile z poprzednich procesów.
Bez ustrukturyzowanych danych kandydat nadal tkwi w systemie, ale wyciągnięcie go na powierzchnię jest niezwykle uciążliwe. A kandydat, którego nie da się znaleźć w odpowiednim momencie, jest warty dokładnie tyle samo, co kandydat, którego w ogóle w bazie nie ma.
To jeden z powodów, dla których uważamy, że parsowanie powinno być traktowane przede wszystkim jako narzędzie do dbania o jakość danych, a dopiero w drugiej kolejności jako narzędzie ułatwiające pracę.
Parser dba o przyszłość Twojej bazy
Kształt każdej bazy rekrutacyjnej zależy od tego, w jaki sposób wprowadzane są do niej dane.
Jeśli proces ten przebiega ręcznie, niespójnie lub powierzchownie, system powoli staje się niezdatny do użytku. Z biegiem czasu rekruterzy po prostu tracą do niego zaufanie. Wracają na LinkedIna i inwestują w nowe ogłoszenia, bo wewnętrzna wyszukiwarka wydaje się nieprzewidywalna.
Dobry parser pomaga temu zapobiec już na samym starcie.
Tworzy mocny fundament pod profil kandydata, relacje firmowe, wyszukiwanie po lokalizacji, skille, przyszłe automatyzacje i ponowne wykorzystanie bazy. Pomaga utrzymać użyteczność systemu nie tylko dziś, ale także za wiele miesięcy i lat.
Oczywiście, to nie oznacza, że każdy profil będzie nieskazitelny. Formaty życiorysów są nieszablonowe. Informacje nie zawsze są kompletne. Ludzka weryfikacja wciąż odgrywa istotną rolę. Ale celem wcale nie jest wykluczenie rekrutera z tego procesu. Celem jest wyeliminowanie niepotrzebnej, powtarzalnej „dłubaniny” i stworzenie znacznie lepszego punktu wyjścia.
Parsowanie CV to nie tylko uciążliwa administracja
Bardzo łatwo jest bagatelizować wdrożenie CV Parsera, bo brzmi to mocno operacyjnie. Wgraj CV. Wyciągnij dane. Utwórz profil.
W rzeczywistości proces ten dotyka czegoś o wiele większego: jakości samego systemu rekrutacyjnego.
Jeśli dane kandydatów są słabe, wyszukiwanie staje się uciążliwe.
Jeśli brakuje powiązań z firmami, mapowanie rynku kuleje.
Jeśli umiejętności nie zostały zunifikowane, matchowanie kandydatów zawodzi.
Jeśli brakuje lokalizacji, filtry stają się bezużyteczne.
Jeśli profile są dziurawe, Pule Talentów tracą na wartości.
Jeśli baza nie budzi zaufania – zespół znów musi zaczynać od nowa.
Właśnie dlatego CV Parser w Recruitify to nie tylko narzędzie do oszczędzenia kilku minut podczas dodawania aplikacji. To mechanizm, który dba o to, by bezcenne informacje z życiorysu nie utknęły w martwym dokumencie, lecz stały się w pełni ustrukturyzowane, wyszukiwalne i powiązane z całym ekosystemem.
Dlaczego zaprojektowaliśmy to w ten sposób
Zbudowaliśmy nasz CV Parser właśnie tak, ponieważ wiemy, że zespoły rekrutacyjne już teraz posiadają znacznie więcej informacji, niż same zdają sobie sprawę. Problemem jest to, że lwią część z nich ukryto po plikach, w notatkach i rozrzuconych skrzynkach mailowych.
CV nie powinno być martwym załącznikiem w systemie. Powinno aktywnie współtworzyć profil kandydata, wzbogacać bazę danych, budować biznesowy kontekst firmowy, wspierać direct search, porządkować kompetencje oraz lokalizacje, i realnie ułatwiać pracę rekruterom w przyszłości.
Bo dane rekrutacyjne mają wartość tylko wtedy, gdy można ich w każdej chwili użyć. A w momencie, w którym CV zaczyna pracować jako dane, cały proces rekrutacyjny staje się niesamowicie połączoną, zintegrowaną całością.
Taka właśnie idea przyświecała nam podczas tworzenia CV Parsera w Recruitify: to nie tylko szybsze założenie nowej karty profilowej. To budowanie inteligentnej analityki rekrutacyjnej już od pierwszego kliknięcia myszką.
Aktualizacje i nowości
Bądź na bieżąco z najnowszymi innowacjami, funkcjami i wskazówkami dotyczącymi Recruitify!
Podając swój adres e-mail w ramach formularza zapisu na newsletter wyrażasz zgodę na jego przetwarzanie w celu przesyłania informacji marketingowych dotyczących produktów i usług Administratora. Administratorem Twoich danych osobowych przetwarzanych w powyższym celu jest Recruitify Sp. z o.o. z siedzibą w Warszawie (KRS 0000709889). Więcej informacji na temat zasad przetwarzania danych osobowych i praw osób, których dane dotyczą znajdziesz w dokumencie Polityka prywatności.
Zaktualizowano:
CV Parser: Kiedy CV zaczyna pracować jako dane
Nowości
Iwo Paliszewski
CV Parser: Kiedy CV zaczyna pracować jako dane
Dla wielu zespołów rekrutacyjnych CV wciąż traktowane jest głównie jako dokument.
Coś, co można otworzyć, przeczytać, ocenić, pobrać, przesłać dalej, porównać i zarchiwizować. Często jest to punkt startowy procesu rekrutacji, ale zazwyczaj na tym jego rola się kończy: pozostaje po prostu plikiem podpiętym pod profil kandydata.
Problem w tym, że zespoły rekrutacyjne nie potrzebują wyłącznie dokumentów. Potrzebują użytecznych informacji.
Muszą wiedzieć, jakie umiejętności posiada kandydat, gdzie pracował, jakie firmy widnieją w jego historii, jakie zajmował stanowiska, jakim posługuje się językiem i gdzie się znajduje. A co najważniejsze – jak to wszystko bezproblemowo przeszukiwać, filtrować, łączyć i wykorzystywać w przyszłości.
Właśnie dlatego postrzegamy parsowanie CV jako coś znacznie ważniejszego niż tylko „szybsze wgrywanie życiorysu”.
Dobry parser CV nie powinien służyć jedynie do oszczędzania czasu na ręcznym przepisywaniu danych. Powinien pomagać w zamianie statycznego dokumentu w ustrukturyzowane dane rekrutacyjne. A kiedy CV staje się zbiorem danych, zaczyna realnie pracować na korzyść rekrutera.
CV to znacznie więcej niż tylko dane kontaktowe
Kiedy myślimy o parsowaniu CV, zazwyczaj przychodzą nam do głowy absolutne podstawy: imię i nazwisko, adres e-mail, numer telefonu, stanowisko, wykształcenie i doświadczenie zawodowe.
Oczywiście, to bardzo przydatne. Nikt nie chce ręcznie przeklejać informacji z PDF-a, jeśli system może to zrobić automatycznie. Jednak w rekrutacji prawdziwa wartość CV wykracza daleko poza same dane kontaktowe.
CV to kompletna historia zawodowa. Kryją się w niej firmy, branże, ścieżki kariery, umiejętności, poziom seniority, technologie, języki obce, lokalizacje i mnóstwo pośredniego kontekstu, który może okazać się kluczowy w przyszłości.
Na przykład: jeśli kandydat pracował dla trzech różnych software house'ów, to wysyła nam to konkretny sygnał. Jeśli przeszedł z agencji rekrutacyjnej do wewnętrznego HR-u – to również ma znaczenie. Znaczenie ma też to, czy spędził lata w finansach, ochronie zdrowia, logistyce czy produkcji. Jego lokalizacja jest kluczowa, zwłaszcza gdy rekrutujemy do ról hybrydowych, lokalnych, w pełni zdalnych lub wymagających relokacji.
CV to nie tylko dokument. To mapa profesjonalnych doświadczeń, relacji i rynkowego kontekstu.
Wyzwaniem jest to, że ta mapa zazwyczaj ukryta jest w nieustrukturyzowanym tekście. Dopóki system nie potrafi jej wydobyć, uporządkować i połączyć z resztą bazy danych, większość tej wartości pozostaje uwięziona w pliku.
Ręczne wprowadzanie danych generuje tarcia i niespójności
Rekruterzy zazwyczaj świetnie radzą sobie ze zrozumieniem CV. Problemem nie jest ludzka interpretacja. Problemem jest powtarzalność.
Kiedy rekruter musi ręcznie utworzyć profil kandydata, skopiować dane, dodać historię zatrudnienia, wyłuskać umiejętności, wpisać nazwy firm, dodać lokalizację i odpowiednio to ustrukturyzować – proces staje się wolniejszy i o wiele bardziej niespójny.
Jeden rekruter wpisze „JavaScript”, inny „JS”. Ktoś doda „angielski” jako język, a ktoś inny to pominie, bo w danej roli nie było to wymagane. Jeden rekruter doda Warszawę jako lokalizację, drugi zostawi to pole puste. Ktoś utworzy pełen profil firmy dla poprzedniego pracodawcy, inny zostawi jego nazwę jedynie jako ciąg znaków w notatce.
Pojedynczo te wybory wydają się błahe. Ale z czasem to one kształtują jakość bazy danych.
A jakość bazy ma fundamentalne znaczenie. Wpływa na wyszukiwanie, raportowanie, budowanie pul talentów, direct search, matchowanie kandydatów i możliwość ich ponownego wykorzystania. Jeśli informacje nie zostaną dobrze ustrukturyzowane na samym początku, system bardzo szybko przestaje wzbudzać zaufanie.
Dlatego parsowanie to nie tylko kwestia szybkości. To kwestia spójności danych.
Od pliku CV do pełnoprawnego profilu kandydata
Główny cel CV Parsera w Recruitify jest prosty: pomóc rekruterom w tworzeniu profili kandydatów szybciej i przy minimalnym nakładzie pracy ręcznej.
Po wgraniu życiorysu system wyciąga kluczowe informacje i buduje na ich podstawie gotowy profil. Obejmuje to podstawowe dane, doświadczenie, wykształcenie, umiejętności, języki, lokalizację i wszelkie inne istotne szczegóły, które można od razu wykorzystać w procesie rekrutacji.
Ma to potężne znaczenie, ponieważ pierwsze kilka minut pracy z kandydatem często decyduje o tym, czy baza będzie użyteczna w przyszłości.
Jeśli profil jest niekompletny, trudny do znalezienia, brakuje w nim kluczowych umiejętności lub lokalizacji, rekruter nadal poprowadzi bieżący proces, ale kandydat traci na wartości w kontekście przyszłych projektów. Dobrze sparsowany profil ułatwia znalezienie, porównanie, zakwalifikowanie i powrót do kandydata przy kolejnych poszukiwaniach.
CV przestaje być tylko załącznikiem. Staje się integralną częścią systemu rekrutacyjnego.
Dane o lokalizacji pomagają uporządkować bazę
Lokalizacja to jeden z tych detali, które wydają się prozaiczne, ale w rekrutacji potrafią zrobić kolosalną różnicę.
Wiele poszukiwań nadal dyktuje geografia. Nawet w erze pracy zdalnej, liczne role mają charakter hybrydowy, regionalny, są przypisane do konkretnego klienta, kraju, biura lub strefy czasowej. Ze względów prawnych, płacowych lub językowych – lokalizacja wciąż ma ogromne znaczenie.
Jeśli lokalizacja kandydata jest ukryta wyłącznie w tekście CV, rekruterzy mogą ją łatwo przeoczyć podczas przyszłych wyszukiwań. Jeśli jednak jest ustrukturyzowana w profilu – filtrowanie bazy staje się banalnie proste.
Właśnie dlatego ekstrakcja lokalizacji jest tak ważna. Parser, który pomaga przypisać właściwe miejsce zamieszkania do profilu, dba o lepszą organizację całej bazy. Czyni ją czystszą i bardziej użyteczną dla przyszłych ról. Pozwala też uniknąć niepotrzebnego ręcznego przeglądania dziesiątek profili, gdy zespół na cito potrzebuje kandydata z konkretnego regionu.
I znów – tu nie chodzi o wypełnienie kolejnego okienka w systemie. Chodzi o to, by dane kandydata były w pełni gotowe do użycia.
Budowanie bazy firm na podstawie CV kandydatów
Jednym z obszarów, na którym szczególnie zależało nam w Recruitify, są relacje między kandydatami a firmami.
W wielu systemach rekrutacyjnych firmy istnieją tylko wtedy, gdy ktoś z zespołu ręcznie doda je jako klientów lub pracodawców. A przecież CV kandydatów są wręcz naszpikowane informacjami o organizacjach biznesowych. Historia zatrudnienia ujawnia, gdzie kandydat pracował, jakie firmy liczą się na danym rynku talentów i jak płynnie ludzie przemieszczają się między pracodawcami.
To dlatego nasz parser potrafi również tworzyć rekordy firm bezpośrednio z życiorysów kandydatów.
Jeśli CV kandydata wymienia poprzednich pracodawców, system automatycznie wyciąga ich nazwy, pomagając utworzyć lub połączyć je wewnątrz bazy danych. Kandydat zostaje trwale powiązany z tymi organizacjami jako ich obecny lub były pracownik.
Może to brzmieć jak drobny techniczny detal, ale dla zespołów rekrutacyjnych – zwłaszcza agencji i headhunterów – jest to funkcjonalność na wagę złota. Bo rekrutacja to nie tylko analizowanie pojedynczych kandydatów. To głębokie zrozumienie całego rynku.
Budowanie struktur powiązań dla Direct Search
Direct search mocno opiera się na kontekście. Rekruterzy chcą wiedzieć nie tylko kim jest kandydat, ale gdzie pracował, które firmy „produkują” określone typy talentów, które organizacje mają znaczenie w danym sektorze i jak kandydaci są ze sobą powiązani.
Gdy system tworzy struktury firm z CV i od razu łączy z nimi kandydatów, baza danych staje się czymś więcej niż tylko listą profili. Zaczyna przekształcać się w mapę powiązań rynkowych.
To nieoceniona przewaga, gdy rekruterzy pracują nad podobnymi rolami, mapują konkurencję, budują wywiad rynkowy lub szukają talentów z doświadczeniem w specyficznym środowisku biznesowym.
Dla przykładu: rekruter może chcieć znaleźć osoby, które pracowały w określonych firmach technologicznych, consultingowych, medycznych czy produkcyjnych. Jeśli ta informacja żyje tylko w pliku PDF, jest praktycznie bezużyteczna. Jeśli jest zmapowana w systemie – staje się łatwa do wyszukania.
A to całkowicie zmienia wartość całej bazy danych.
Ekstrakcja umiejętności zamienia doświadczenie w wyszukiwalne sygnały
Umiejętności (skills) to jedna z najważniejszych składowych danych rekrutacyjnych, ale jednocześnie obszar, który najłatwiej zepsuć złym tagowaniem.
Kandydaci opisują swoje kompetencje w najróżniejszy sposób. Różnią się formaty dokumentów. Jedni mają świetnie wypunktowane listy technologii. Inni przemycają je w rozwlekłych opisach stanowisk. Niektórzy używają skrótów, inni pełnych nazw.
Parser pomaga wyłuskać te umiejętności i zunifikować je jako użyteczne tagi wewnątrz systemu.
To kluczowe dla zaawansowanego wyszukiwania, budowy Puli Talentów (Talent Pools), raportowania i przyszłych projektów. Jeśli umiejętności zostaną odpowiednio wychwycone, rekruterzy mogą wrócić do bazy i błyskawicznie odnaleźć pasujących ludzi, zamiast za każdym razem zaczynać od zewnętrznego sourcingu.
Ale to nie jest po prostu dodanie większej liczby słów kluczowych. To tworzenie ustrukturyzowanych sygnałów.
Gdy połączymy kompetencje, doświadczenie, firmy, języki, lokalizacje i historię, baza zyskuje potężną moc. Rekruterzy mogą wyszukiwać dane z większą pewnością, skuteczniej segmentować kandydatów i identyfikować ludzi, którzy w przeciwnym razie na zawsze zniknęliby w czeluściach starych plików.
Lepsze dane to lepsze ponowne wykorzystanie (Reuse)
Baza rekrutacyjna jest wartościowa dopiero wtedy, gdy można ją użyć ponownie. Nie tylko przy okazji jednego, bieżącego projektu, ale przy przyszłych wakatach, u różnych klientów, przy zasilaniu pul talentów i budowaniu wieloletnich relacji z kandydatem.
To właśnie w takich momentach ustrukturyzowane dane z CV okazują się krytyczne. Jeśli parser wydobędzie szczegóły z dokumentu, rekruter może na ich podstawie tworzyć Dynamiczne Pule Talentów, odpalać zaawansowane wyszukiwania i identyfikować świetne profile z poprzednich procesów.
Bez ustrukturyzowanych danych kandydat nadal tkwi w systemie, ale wyciągnięcie go na powierzchnię jest niezwykle uciążliwe. A kandydat, którego nie da się znaleźć w odpowiednim momencie, jest warty dokładnie tyle samo, co kandydat, którego w ogóle w bazie nie ma.
To jeden z powodów, dla których uważamy, że parsowanie powinno być traktowane przede wszystkim jako narzędzie do dbania o jakość danych, a dopiero w drugiej kolejności jako narzędzie ułatwiające pracę.
Parser dba o przyszłość Twojej bazy
Kształt każdej bazy rekrutacyjnej zależy od tego, w jaki sposób wprowadzane są do niej dane.
Jeśli proces ten przebiega ręcznie, niespójnie lub powierzchownie, system powoli staje się niezdatny do użytku. Z biegiem czasu rekruterzy po prostu tracą do niego zaufanie. Wracają na LinkedIna i inwestują w nowe ogłoszenia, bo wewnętrzna wyszukiwarka wydaje się nieprzewidywalna.
Dobry parser pomaga temu zapobiec już na samym starcie.
Tworzy mocny fundament pod profil kandydata, relacje firmowe, wyszukiwanie po lokalizacji, skille, przyszłe automatyzacje i ponowne wykorzystanie bazy. Pomaga utrzymać użyteczność systemu nie tylko dziś, ale także za wiele miesięcy i lat.
Oczywiście, to nie oznacza, że każdy profil będzie nieskazitelny. Formaty życiorysów są nieszablonowe. Informacje nie zawsze są kompletne. Ludzka weryfikacja wciąż odgrywa istotną rolę. Ale celem wcale nie jest wykluczenie rekrutera z tego procesu. Celem jest wyeliminowanie niepotrzebnej, powtarzalnej „dłubaniny” i stworzenie znacznie lepszego punktu wyjścia.
Parsowanie CV to nie tylko uciążliwa administracja
Bardzo łatwo jest bagatelizować wdrożenie CV Parsera, bo brzmi to mocno operacyjnie. Wgraj CV. Wyciągnij dane. Utwórz profil.
W rzeczywistości proces ten dotyka czegoś o wiele większego: jakości samego systemu rekrutacyjnego.
Jeśli dane kandydatów są słabe, wyszukiwanie staje się uciążliwe.
Jeśli brakuje powiązań z firmami, mapowanie rynku kuleje.
Jeśli umiejętności nie zostały zunifikowane, matchowanie kandydatów zawodzi.
Jeśli brakuje lokalizacji, filtry stają się bezużyteczne.
Jeśli profile są dziurawe, Pule Talentów tracą na wartości.
Jeśli baza nie budzi zaufania – zespół znów musi zaczynać od nowa.
Właśnie dlatego CV Parser w Recruitify to nie tylko narzędzie do oszczędzenia kilku minut podczas dodawania aplikacji. To mechanizm, który dba o to, by bezcenne informacje z życiorysu nie utknęły w martwym dokumencie, lecz stały się w pełni ustrukturyzowane, wyszukiwalne i powiązane z całym ekosystemem.
Dlaczego zaprojektowaliśmy to w ten sposób
Zbudowaliśmy nasz CV Parser właśnie tak, ponieważ wiemy, że zespoły rekrutacyjne już teraz posiadają znacznie więcej informacji, niż same zdają sobie sprawę. Problemem jest to, że lwią część z nich ukryto po plikach, w notatkach i rozrzuconych skrzynkach mailowych.
CV nie powinno być martwym załącznikiem w systemie. Powinno aktywnie współtworzyć profil kandydata, wzbogacać bazę danych, budować biznesowy kontekst firmowy, wspierać direct search, porządkować kompetencje oraz lokalizacje, i realnie ułatwiać pracę rekruterom w przyszłości.
Bo dane rekrutacyjne mają wartość tylko wtedy, gdy można ich w każdej chwili użyć. A w momencie, w którym CV zaczyna pracować jako dane, cały proces rekrutacyjny staje się niesamowicie połączoną, zintegrowaną całością.
Taka właśnie idea przyświecała nam podczas tworzenia CV Parsera w Recruitify: to nie tylko szybsze założenie nowej karty profilowej. To budowanie inteligentnej analityki rekrutacyjnej już od pierwszego kliknięcia myszką.
Aktualizacje i nowości
Bądź na bieżąco z najnowszymi innowacjami, funkcjami i wskazówkami dotyczącymi Recruitify!
Podając swój adres e-mail w ramach formularza zapisu na newsletter wyrażasz zgodę na jego przetwarzanie w celu przesyłania informacji marketingowych dotyczących produktów i usług Administratora. Administratorem Twoich danych osobowych przetwarzanych w powyższym celu jest Recruitify Sp. z o.o. z siedzibą w Warszawie (KRS 0000709889). Więcej informacji na temat zasad przetwarzania danych osobowych i praw osób, których dane dotyczą znajdziesz w dokumencie Polityka prywatności.

Zobacz również

ATS
11 cze 2026
Co to jest ATS? Kompletny przewodnik po systemach rekrutacyjnych (2026)
Definicja, historia, funkcje, AI, agenci i wszystko, co musisz wiedzieć przed wyborem systemu ATS dla HR, agencji i kontraktingu
Zobacz więcej

Proces rekrutacyjny
8 cze 2026
CRM w agencji rekrutacyjnej: Bo klient to też część procesu zatrudnienia
CRM w agencji rekrutacyjnej: Bo klient to też część procesu zatrudnienia
Zobacz więcej

Proces rekrutacyjny
5 cze 2026
Projekt zamknięty. Kandydat zatrudniony. Ale co dzieje się z pozostałymi 136 osobami?
Projekt zamknięty. Kandydat zatrudniony. Ale co dzieje się z pozostałymi 136 osobami?
Zobacz więcej
ATS
11 cze 2026
Co to jest ATS? Kompletny przewodnik po systemach rekrutacyjnych (2026)
Definicja, historia, funkcje, AI, agenci i wszystko, co musisz wiedzieć przed wyborem systemu ATS dla HR, agencji i kontraktingu
Zobacz więcej
Proces rekrutacyjny
8 cze 2026
CRM w agencji rekrutacyjnej: Bo klient to też część procesu zatrudnienia
CRM w agencji rekrutacyjnej: Bo klient to też część procesu zatrudnienia
Zobacz więcej

