🔥
Contracting
Explore the new contractor management module
🔥
Contracting
Explore the new contractor management module
🔥
Contracting
Explore the new contractor management module
🔥
Contracting
Explore the new contractor management module
Last updated:
CV Parser: When a CV Starts Working as Data

Innovations

Iwo Paliszewski
For many recruitment teams, a CV is still treated mainly as a document.
Something to open, read, review, download, forward, compare, and store. It is often the starting point of the recruitment process, but it usually remains exactly that: a file attached to a candidate profile.
The problem is that recruitment teams do not only need documents. They need usable information.
They need to know what skills a candidate has, where they worked, which companies appear in their career history, what roles they held, what experience they bring, what languages they speak, where they are located, and how all of this can be searched, filtered, connected, and reused later.
That is why we see CV parsing as something much more important than “uploading a CV faster.”
A good CV parser should not only save time on manual data entry. It should help turn a static document into structured recruitment data. And once a CV becomes data, it can start working for the recruiter.
A CV contains more than candidate details
When people think about CV parsing, they usually think about the basics: name, email address, phone number, job title, education, and work experience.
That is useful, of course. Nobody wants to manually copy information from a PDF into a system if the system can do it automatically. But in recruitment, the real value of a CV goes far beyond contact details.
A CV contains a professional history. It contains companies, industries, career paths, skills, seniority, technologies, languages, locations, and a lot of indirect context that can become useful later.
For example, if a candidate worked for three software houses, that tells us something. If they moved from agency recruitment into internal HR, that tells us something. If they spent several years in finance, healthcare, logistics, or manufacturing, that also matters. If they are based in a specific city or region, that matters too, especially when recruiters are working with local, hybrid, remote, or relocation-based roles.
The CV is not just a document. It is a map of professional experience, relationships, and market context.
The challenge is that this map is usually hidden inside unstructured text. Unless the system can extract it, organize it, and connect it to the rest of the database, most of that value stays locked inside the file.
Manual data entry creates friction and inconsistency
Recruiters are usually good at understanding CVs. The problem is not interpretation. The problem is repetition.
When a recruiter has to manually create a candidate profile, copy contact details, add employment history, identify skills, type company names, add locations, add notes, and structure data by hand, the process becomes slower and more inconsistent.
One recruiter may write “JavaScript.” Another may write “JS.” One may add “English” as a language. Another may skip it because it was not relevant to the current role. One recruiter may add Warsaw as the candidate’s location. Another may leave the location blank. One may create a company record. Another may leave the previous employer only as text inside the CV.
Individually, these choices seem small. Over time, they shape the quality of the database.
And database quality matters. It affects search, reporting, talent pooling, direct search, matching, future sourcing, and the ability to reuse candidates later. If candidate information is not structured well at the beginning, the system becomes harder to trust later.
That is why parsing is not only about speed. It is also about consistency.
From a CV file to a candidate profile
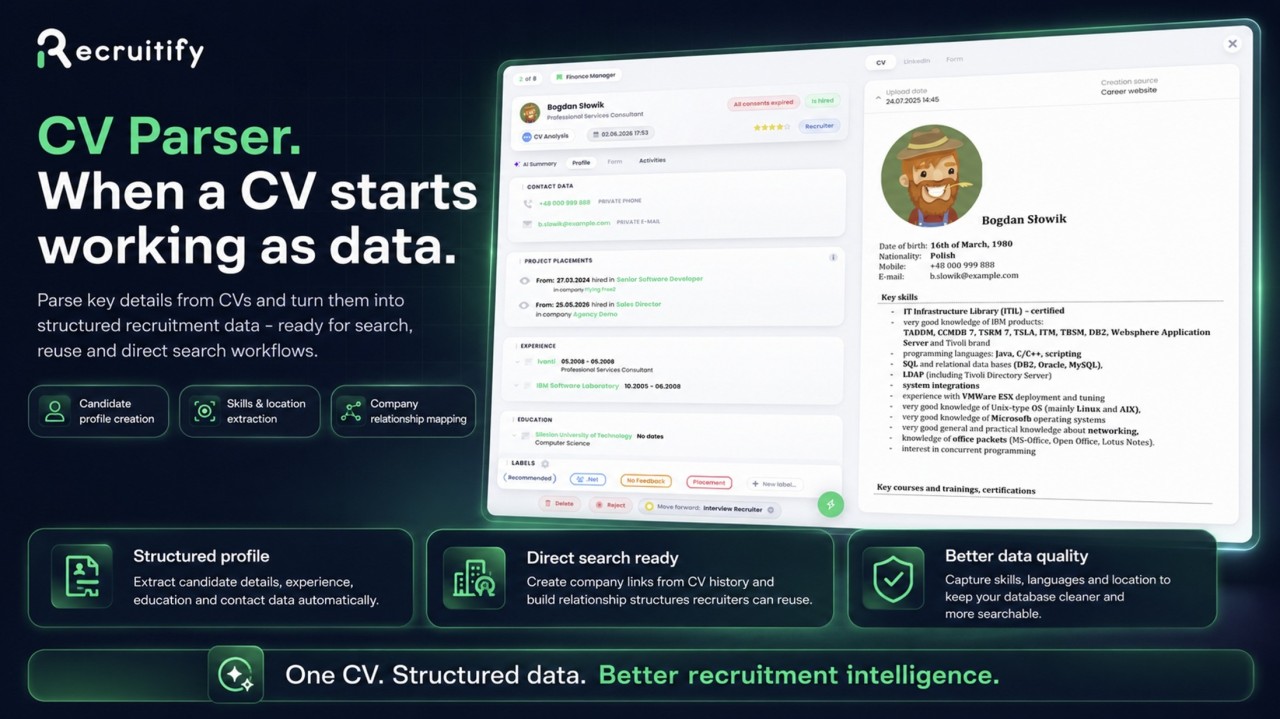
The first purpose of the CV Parser in Recruitify is simple: help recruiters create candidate profiles faster and with less manual work.
When a CV is uploaded, the system extracts key information and uses it to build a candidate profile. This includes basic details, experience, education, skills, languages, location, and other relevant information that can be used inside the recruitment process.
This matters because the first few minutes of working with a candidate often decide whether the database will be useful later.
If the profile is incomplete, difficult to search, missing important skills, or missing location data, the recruiter may still be able to handle the current process, but the candidate becomes less valuable for the future. A properly parsed profile makes the candidate easier to find, compare, shortlist, contact, filter by location, and reuse in future projects.
The CV stops being just an attachment. It becomes part of the recruitment system.
Location data helps organize the database
Location is one of those details that may seem simple, but in recruitment it can make a big difference.
Many searches are still shaped by geography. Some roles are fully remote, but many are hybrid, local, regional, client-specific, or tied to a certain country, city, office, or time zone. Even in remote recruitment, location can matter because of legal, payroll, language, availability, or client requirements.
If candidate location is hidden only inside the CV, recruiters may miss it during future searches. If it is structured in the candidate profile, it becomes much easier to search and filter the database.
That is why location extraction matters.
A parser that helps add the right location to a candidate profile supports better database organization. It makes the database cleaner, more searchable, and more useful for future roles. It also helps recruiters avoid unnecessary manual checking when they need candidates from a specific region or available for a particular work model.
Again, this is not only about filling in another field.
It is about making candidate data usable.
Creating companies from candidate CVs
One of the areas we care about in Recruitify is the relationship between candidates and companies.
In many recruitment systems, companies exist only as clients or employers manually added by the team. But candidate CVs already contain a huge amount of company information. Every work history section can reveal where a candidate has worked, what organizations are relevant in a given talent market, and how people move between employers.
That is why our parser can also create company records from candidate CVs.
If a candidate’s CV includes previous employers, the system can extract those company names and help create or connect them within the database. The candidate can then be associated with those companies as a current or former employee.
This may sound like a small technical detail, but for recruitment teams, especially agencies and direct search teams, it can be extremely valuable.
Because recruitment is not only about individual candidates. It is also about understanding the market.
Building relationship structures for direct search
Direct search depends heavily on context.
Recruiters want to know not only who a candidate is, but also where they worked, which companies produce certain types of talent, which organizations are relevant in a sector, and how candidates are connected to the market.
When the system creates company structures from CVs and links candidates to those companies, the database becomes more than a list of profiles. It starts to become a map of relationships.
This is especially useful when recruiters are working on similar roles, mapping competitors, building market intelligence, or searching for candidates with experience in specific company environments.
For example, a recruiter may want to find people who have worked in certain technology companies, consulting firms, healthcare organizations, manufacturing businesses, recruitment agencies, or financial institutions. If that information exists only inside CV files, it is difficult to use. If it is structured in the system, it becomes searchable.
And that changes how valuable the database becomes.
Skills extraction turns experience into searchable signals
Skills are one of the most important parts of recruitment data, but they are also one of the easiest to structure poorly.
Candidates describe skills differently. CV formats vary. Some candidates list technologies clearly. Others mention them only inside role descriptions. Some use abbreviations. Others use full names.
A parser helps extract these skills and make them usable inside the system.
This is important for search, matching, talent pools, reporting, and future recruitment projects. If skills are captured properly, recruiters can return to the database and find relevant candidates faster instead of starting from external sourcing every time.
But again, this is not only about adding more keywords. It is about creating structured signals.
When skills, experience, companies, languages, location, and candidate history are all connected, the database becomes much more useful. Recruiters can search with more confidence, segment candidates more effectively, and identify people who might otherwise stay hidden inside old CV files.
Better data means better reuse
A recruitment database becomes valuable when it can be reused.
Not just for one project, but across future roles, similar searches, client needs, talent pools, and long-term candidate relationships.
This is where structured CV data becomes critical. If the CV parser extracts skills, languages, companies, locations, experience, and professional history, recruiters can later use that data to build Talent Pools, run advanced searches, identify strong candidates from previous processes, and support matching between candidates and roles.
Without structured data, the candidate may still exist in the database, but they are much harder to find. And a candidate who cannot be found at the right moment is almost the same as a candidate who was never added.
That is one of the reasons we believe parsing should be treated as a data quality feature, not just a convenience feature.
It also improves the future of the database
Every recruitment database is shaped by the way data enters it.
If information enters the system manually, inconsistently, or incompletely, the database slowly becomes harder to use. Over time, recruiters stop trusting it. They return to LinkedIn, external databases, and new job ads because internal search feels unreliable.
A good parser helps prevent that from the start.
It creates a stronger foundation for the candidate profile, company relationships, location-based search, skill search, future automation, and candidate reuse. It helps the database stay useful not only today, but also months or years later.
That does not mean every profile will be perfect. CVs differ. Formats differ. Candidate information is not always complete. Human review still matters.
But the goal is not to remove recruiters from the process. The goal is to remove unnecessary manual work and create better starting data.
CV parsing is not only administration
It is easy to underestimate CV parsing because it sounds operational.
Upload CV. Extract data. Create profile.
But in reality, it touches something much bigger: the quality of the recruitment system itself.
If candidate data is poor, search becomes weaker. If company relationships are missing, market mapping becomes harder. If skills are not extracted, matching becomes less reliable. If location data is missing, filtering becomes less precise. If profiles are incomplete, Talent Pools lose value. If the database cannot be trusted, recruiters start again from scratch.
That is why the CV Parser in Recruitify is not just about saving a few minutes when adding a candidate. It is about making sure that the information inside a CV does not stay trapped inside a document, but becomes structured, searchable, connected, and reusable.
Why we built it this way
We built our CV Parser this way because recruitment teams already have more information than they often realize. The problem is that too much of this information is hidden in files, notes, inboxes, and unstructured text.
A CV should not be a dead attachment in the system. It should help build the candidate profile, enrich the database, create company context, support direct search, extract skills and languages, organize location data, and make future searches easier.
Because recruitment data is only valuable when it can be used.
And the moment a CV starts working as data, the whole recruitment process becomes more connected.
That is the idea behind the CV Parser in Recruitify: not just faster profile creation, but better recruitment intelligence from the very first upload.


News & Updates
Stay up-to-date with the latest innovations, features, and tips about Recruitify!
By providing your email address within the newsletter sign-up form, you confirm its processing to send marketing information regarding the Administrator’s products and services. The Administrator of your personal data processed for the abovementioned purposes is Recruitify Spółka z o.o., based in Warsaw, Poland (KRS 0000709889). For more information on the principles of personal data processing and the rights of data subjects, please check the Privacy Policy.

Last updated:
CV Parser: When a CV Starts Working as Data
Innovations
Iwo Paliszewski
For many recruitment teams, a CV is still treated mainly as a document.
Something to open, read, review, download, forward, compare, and store. It is often the starting point of the recruitment process, but it usually remains exactly that: a file attached to a candidate profile.
The problem is that recruitment teams do not only need documents. They need usable information.
They need to know what skills a candidate has, where they worked, which companies appear in their career history, what roles they held, what experience they bring, what languages they speak, where they are located, and how all of this can be searched, filtered, connected, and reused later.
That is why we see CV parsing as something much more important than “uploading a CV faster.”
A good CV parser should not only save time on manual data entry. It should help turn a static document into structured recruitment data. And once a CV becomes data, it can start working for the recruiter.
A CV contains more than candidate details
When people think about CV parsing, they usually think about the basics: name, email address, phone number, job title, education, and work experience.
That is useful, of course. Nobody wants to manually copy information from a PDF into a system if the system can do it automatically. But in recruitment, the real value of a CV goes far beyond contact details.
A CV contains a professional history. It contains companies, industries, career paths, skills, seniority, technologies, languages, locations, and a lot of indirect context that can become useful later.
For example, if a candidate worked for three software houses, that tells us something. If they moved from agency recruitment into internal HR, that tells us something. If they spent several years in finance, healthcare, logistics, or manufacturing, that also matters. If they are based in a specific city or region, that matters too, especially when recruiters are working with local, hybrid, remote, or relocation-based roles.
The CV is not just a document. It is a map of professional experience, relationships, and market context.
The challenge is that this map is usually hidden inside unstructured text. Unless the system can extract it, organize it, and connect it to the rest of the database, most of that value stays locked inside the file.
Manual data entry creates friction and inconsistency
Recruiters are usually good at understanding CVs. The problem is not interpretation. The problem is repetition.
When a recruiter has to manually create a candidate profile, copy contact details, add employment history, identify skills, type company names, add locations, add notes, and structure data by hand, the process becomes slower and more inconsistent.
One recruiter may write “JavaScript.” Another may write “JS.” One may add “English” as a language. Another may skip it because it was not relevant to the current role. One recruiter may add Warsaw as the candidate’s location. Another may leave the location blank. One may create a company record. Another may leave the previous employer only as text inside the CV.
Individually, these choices seem small. Over time, they shape the quality of the database.
And database quality matters. It affects search, reporting, talent pooling, direct search, matching, future sourcing, and the ability to reuse candidates later. If candidate information is not structured well at the beginning, the system becomes harder to trust later.
That is why parsing is not only about speed. It is also about consistency.
From a CV file to a candidate profile
The first purpose of the CV Parser in Recruitify is simple: help recruiters create candidate profiles faster and with less manual work.
When a CV is uploaded, the system extracts key information and uses it to build a candidate profile. This includes basic details, experience, education, skills, languages, location, and other relevant information that can be used inside the recruitment process.
This matters because the first few minutes of working with a candidate often decide whether the database will be useful later.
If the profile is incomplete, difficult to search, missing important skills, or missing location data, the recruiter may still be able to handle the current process, but the candidate becomes less valuable for the future. A properly parsed profile makes the candidate easier to find, compare, shortlist, contact, filter by location, and reuse in future projects.
The CV stops being just an attachment. It becomes part of the recruitment system.
Location data helps organize the database
Location is one of those details that may seem simple, but in recruitment it can make a big difference.
Many searches are still shaped by geography. Some roles are fully remote, but many are hybrid, local, regional, client-specific, or tied to a certain country, city, office, or time zone. Even in remote recruitment, location can matter because of legal, payroll, language, availability, or client requirements.
If candidate location is hidden only inside the CV, recruiters may miss it during future searches. If it is structured in the candidate profile, it becomes much easier to search and filter the database.
That is why location extraction matters.
A parser that helps add the right location to a candidate profile supports better database organization. It makes the database cleaner, more searchable, and more useful for future roles. It also helps recruiters avoid unnecessary manual checking when they need candidates from a specific region or available for a particular work model.
Again, this is not only about filling in another field.
It is about making candidate data usable.
Creating companies from candidate CVs
One of the areas we care about in Recruitify is the relationship between candidates and companies.
In many recruitment systems, companies exist only as clients or employers manually added by the team. But candidate CVs already contain a huge amount of company information. Every work history section can reveal where a candidate has worked, what organizations are relevant in a given talent market, and how people move between employers.
That is why our parser can also create company records from candidate CVs.
If a candidate’s CV includes previous employers, the system can extract those company names and help create or connect them within the database. The candidate can then be associated with those companies as a current or former employee.
This may sound like a small technical detail, but for recruitment teams, especially agencies and direct search teams, it can be extremely valuable.
Because recruitment is not only about individual candidates. It is also about understanding the market.
Building relationship structures for direct search
Direct search depends heavily on context.
Recruiters want to know not only who a candidate is, but also where they worked, which companies produce certain types of talent, which organizations are relevant in a sector, and how candidates are connected to the market.
When the system creates company structures from CVs and links candidates to those companies, the database becomes more than a list of profiles. It starts to become a map of relationships.
This is especially useful when recruiters are working on similar roles, mapping competitors, building market intelligence, or searching for candidates with experience in specific company environments.
For example, a recruiter may want to find people who have worked in certain technology companies, consulting firms, healthcare organizations, manufacturing businesses, recruitment agencies, or financial institutions. If that information exists only inside CV files, it is difficult to use. If it is structured in the system, it becomes searchable.
And that changes how valuable the database becomes.
Skills extraction turns experience into searchable signals
Skills are one of the most important parts of recruitment data, but they are also one of the easiest to structure poorly.
Candidates describe skills differently. CV formats vary. Some candidates list technologies clearly. Others mention them only inside role descriptions. Some use abbreviations. Others use full names.
A parser helps extract these skills and make them usable inside the system.
This is important for search, matching, talent pools, reporting, and future recruitment projects. If skills are captured properly, recruiters can return to the database and find relevant candidates faster instead of starting from external sourcing every time.
But again, this is not only about adding more keywords. It is about creating structured signals.
When skills, experience, companies, languages, location, and candidate history are all connected, the database becomes much more useful. Recruiters can search with more confidence, segment candidates more effectively, and identify people who might otherwise stay hidden inside old CV files.
Better data means better reuse
A recruitment database becomes valuable when it can be reused.
Not just for one project, but across future roles, similar searches, client needs, talent pools, and long-term candidate relationships.
This is where structured CV data becomes critical. If the CV parser extracts skills, languages, companies, locations, experience, and professional history, recruiters can later use that data to build Talent Pools, run advanced searches, identify strong candidates from previous processes, and support matching between candidates and roles.
Without structured data, the candidate may still exist in the database, but they are much harder to find. And a candidate who cannot be found at the right moment is almost the same as a candidate who was never added.
That is one of the reasons we believe parsing should be treated as a data quality feature, not just a convenience feature.
It also improves the future of the database
Every recruitment database is shaped by the way data enters it.
If information enters the system manually, inconsistently, or incompletely, the database slowly becomes harder to use. Over time, recruiters stop trusting it. They return to LinkedIn, external databases, and new job ads because internal search feels unreliable.
A good parser helps prevent that from the start.
It creates a stronger foundation for the candidate profile, company relationships, location-based search, skill search, future automation, and candidate reuse. It helps the database stay useful not only today, but also months or years later.
That does not mean every profile will be perfect. CVs differ. Formats differ. Candidate information is not always complete. Human review still matters.
But the goal is not to remove recruiters from the process. The goal is to remove unnecessary manual work and create better starting data.
CV parsing is not only administration
It is easy to underestimate CV parsing because it sounds operational.
Upload CV. Extract data. Create profile.
But in reality, it touches something much bigger: the quality of the recruitment system itself.
If candidate data is poor, search becomes weaker. If company relationships are missing, market mapping becomes harder. If skills are not extracted, matching becomes less reliable. If location data is missing, filtering becomes less precise. If profiles are incomplete, Talent Pools lose value. If the database cannot be trusted, recruiters start again from scratch.
That is why the CV Parser in Recruitify is not just about saving a few minutes when adding a candidate. It is about making sure that the information inside a CV does not stay trapped inside a document, but becomes structured, searchable, connected, and reusable.
Why we built it this way
We built our CV Parser this way because recruitment teams already have more information than they often realize. The problem is that too much of this information is hidden in files, notes, inboxes, and unstructured text.
A CV should not be a dead attachment in the system. It should help build the candidate profile, enrich the database, create company context, support direct search, extract skills and languages, organize location data, and make future searches easier.
Because recruitment data is only valuable when it can be used.
And the moment a CV starts working as data, the whole recruitment process becomes more connected.
That is the idea behind the CV Parser in Recruitify: not just faster profile creation, but better recruitment intelligence from the very first upload.
News & Updates
Stay up-to-date with the latest innovations, features, and tips about Recruitify!
By providing your email address within the newsletter sign-up form, you confirm its processing to send marketing information regarding the Administrator’s products and services. The Administrator of your personal data processed for the abovementioned purposes is Recruitify Spółka z o.o., based in Warsaw, Poland (KRS 0000709889). For more information on the principles of personal data processing and the rights of data subjects, please check the Privacy Policy.
Last updated:
CV Parser: When a CV Starts Working as Data
Innovations
Iwo Paliszewski
For many recruitment teams, a CV is still treated mainly as a document.
Something to open, read, review, download, forward, compare, and store. It is often the starting point of the recruitment process, but it usually remains exactly that: a file attached to a candidate profile.
The problem is that recruitment teams do not only need documents. They need usable information.
They need to know what skills a candidate has, where they worked, which companies appear in their career history, what roles they held, what experience they bring, what languages they speak, where they are located, and how all of this can be searched, filtered, connected, and reused later.
That is why we see CV parsing as something much more important than “uploading a CV faster.”
A good CV parser should not only save time on manual data entry. It should help turn a static document into structured recruitment data. And once a CV becomes data, it can start working for the recruiter.
A CV contains more than candidate details
When people think about CV parsing, they usually think about the basics: name, email address, phone number, job title, education, and work experience.
That is useful, of course. Nobody wants to manually copy information from a PDF into a system if the system can do it automatically. But in recruitment, the real value of a CV goes far beyond contact details.
A CV contains a professional history. It contains companies, industries, career paths, skills, seniority, technologies, languages, locations, and a lot of indirect context that can become useful later.
For example, if a candidate worked for three software houses, that tells us something. If they moved from agency recruitment into internal HR, that tells us something. If they spent several years in finance, healthcare, logistics, or manufacturing, that also matters. If they are based in a specific city or region, that matters too, especially when recruiters are working with local, hybrid, remote, or relocation-based roles.
The CV is not just a document. It is a map of professional experience, relationships, and market context.
The challenge is that this map is usually hidden inside unstructured text. Unless the system can extract it, organize it, and connect it to the rest of the database, most of that value stays locked inside the file.
Manual data entry creates friction and inconsistency
Recruiters are usually good at understanding CVs. The problem is not interpretation. The problem is repetition.
When a recruiter has to manually create a candidate profile, copy contact details, add employment history, identify skills, type company names, add locations, add notes, and structure data by hand, the process becomes slower and more inconsistent.
One recruiter may write “JavaScript.” Another may write “JS.” One may add “English” as a language. Another may skip it because it was not relevant to the current role. One recruiter may add Warsaw as the candidate’s location. Another may leave the location blank. One may create a company record. Another may leave the previous employer only as text inside the CV.
Individually, these choices seem small. Over time, they shape the quality of the database.
And database quality matters. It affects search, reporting, talent pooling, direct search, matching, future sourcing, and the ability to reuse candidates later. If candidate information is not structured well at the beginning, the system becomes harder to trust later.
That is why parsing is not only about speed. It is also about consistency.
From a CV file to a candidate profile
The first purpose of the CV Parser in Recruitify is simple: help recruiters create candidate profiles faster and with less manual work.
When a CV is uploaded, the system extracts key information and uses it to build a candidate profile. This includes basic details, experience, education, skills, languages, location, and other relevant information that can be used inside the recruitment process.
This matters because the first few minutes of working with a candidate often decide whether the database will be useful later.
If the profile is incomplete, difficult to search, missing important skills, or missing location data, the recruiter may still be able to handle the current process, but the candidate becomes less valuable for the future. A properly parsed profile makes the candidate easier to find, compare, shortlist, contact, filter by location, and reuse in future projects.
The CV stops being just an attachment. It becomes part of the recruitment system.
Location data helps organize the database
Location is one of those details that may seem simple, but in recruitment it can make a big difference.
Many searches are still shaped by geography. Some roles are fully remote, but many are hybrid, local, regional, client-specific, or tied to a certain country, city, office, or time zone. Even in remote recruitment, location can matter because of legal, payroll, language, availability, or client requirements.
If candidate location is hidden only inside the CV, recruiters may miss it during future searches. If it is structured in the candidate profile, it becomes much easier to search and filter the database.
That is why location extraction matters.
A parser that helps add the right location to a candidate profile supports better database organization. It makes the database cleaner, more searchable, and more useful for future roles. It also helps recruiters avoid unnecessary manual checking when they need candidates from a specific region or available for a particular work model.
Again, this is not only about filling in another field.
It is about making candidate data usable.
Creating companies from candidate CVs
One of the areas we care about in Recruitify is the relationship between candidates and companies.
In many recruitment systems, companies exist only as clients or employers manually added by the team. But candidate CVs already contain a huge amount of company information. Every work history section can reveal where a candidate has worked, what organizations are relevant in a given talent market, and how people move between employers.
That is why our parser can also create company records from candidate CVs.
If a candidate’s CV includes previous employers, the system can extract those company names and help create or connect them within the database. The candidate can then be associated with those companies as a current or former employee.
This may sound like a small technical detail, but for recruitment teams, especially agencies and direct search teams, it can be extremely valuable.
Because recruitment is not only about individual candidates. It is also about understanding the market.
Building relationship structures for direct search
Direct search depends heavily on context.
Recruiters want to know not only who a candidate is, but also where they worked, which companies produce certain types of talent, which organizations are relevant in a sector, and how candidates are connected to the market.
When the system creates company structures from CVs and links candidates to those companies, the database becomes more than a list of profiles. It starts to become a map of relationships.
This is especially useful when recruiters are working on similar roles, mapping competitors, building market intelligence, or searching for candidates with experience in specific company environments.
For example, a recruiter may want to find people who have worked in certain technology companies, consulting firms, healthcare organizations, manufacturing businesses, recruitment agencies, or financial institutions. If that information exists only inside CV files, it is difficult to use. If it is structured in the system, it becomes searchable.
And that changes how valuable the database becomes.
Skills extraction turns experience into searchable signals
Skills are one of the most important parts of recruitment data, but they are also one of the easiest to structure poorly.
Candidates describe skills differently. CV formats vary. Some candidates list technologies clearly. Others mention them only inside role descriptions. Some use abbreviations. Others use full names.
A parser helps extract these skills and make them usable inside the system.
This is important for search, matching, talent pools, reporting, and future recruitment projects. If skills are captured properly, recruiters can return to the database and find relevant candidates faster instead of starting from external sourcing every time.
But again, this is not only about adding more keywords. It is about creating structured signals.
When skills, experience, companies, languages, location, and candidate history are all connected, the database becomes much more useful. Recruiters can search with more confidence, segment candidates more effectively, and identify people who might otherwise stay hidden inside old CV files.
Better data means better reuse
A recruitment database becomes valuable when it can be reused.
Not just for one project, but across future roles, similar searches, client needs, talent pools, and long-term candidate relationships.
This is where structured CV data becomes critical. If the CV parser extracts skills, languages, companies, locations, experience, and professional history, recruiters can later use that data to build Talent Pools, run advanced searches, identify strong candidates from previous processes, and support matching between candidates and roles.
Without structured data, the candidate may still exist in the database, but they are much harder to find. And a candidate who cannot be found at the right moment is almost the same as a candidate who was never added.
That is one of the reasons we believe parsing should be treated as a data quality feature, not just a convenience feature.
It also improves the future of the database
Every recruitment database is shaped by the way data enters it.
If information enters the system manually, inconsistently, or incompletely, the database slowly becomes harder to use. Over time, recruiters stop trusting it. They return to LinkedIn, external databases, and new job ads because internal search feels unreliable.
A good parser helps prevent that from the start.
It creates a stronger foundation for the candidate profile, company relationships, location-based search, skill search, future automation, and candidate reuse. It helps the database stay useful not only today, but also months or years later.
That does not mean every profile will be perfect. CVs differ. Formats differ. Candidate information is not always complete. Human review still matters.
But the goal is not to remove recruiters from the process. The goal is to remove unnecessary manual work and create better starting data.
CV parsing is not only administration
It is easy to underestimate CV parsing because it sounds operational.
Upload CV. Extract data. Create profile.
But in reality, it touches something much bigger: the quality of the recruitment system itself.
If candidate data is poor, search becomes weaker. If company relationships are missing, market mapping becomes harder. If skills are not extracted, matching becomes less reliable. If location data is missing, filtering becomes less precise. If profiles are incomplete, Talent Pools lose value. If the database cannot be trusted, recruiters start again from scratch.
That is why the CV Parser in Recruitify is not just about saving a few minutes when adding a candidate. It is about making sure that the information inside a CV does not stay trapped inside a document, but becomes structured, searchable, connected, and reusable.
Why we built it this way
We built our CV Parser this way because recruitment teams already have more information than they often realize. The problem is that too much of this information is hidden in files, notes, inboxes, and unstructured text.
A CV should not be a dead attachment in the system. It should help build the candidate profile, enrich the database, create company context, support direct search, extract skills and languages, organize location data, and make future searches easier.
Because recruitment data is only valuable when it can be used.
And the moment a CV starts working as data, the whole recruitment process becomes more connected.
That is the idea behind the CV Parser in Recruitify: not just faster profile creation, but better recruitment intelligence from the very first upload.
News & Updates
Stay up-to-date with the latest innovations, features, and tips about Recruitify!
By providing your email address within the newsletter sign-up form, you confirm its processing to send marketing information regarding the Administrator’s products and services. The Administrator of your personal data processed for the abovementioned purposes is Recruitify Spółka z o.o., based in Warsaw, Poland (KRS 0000709889). For more information on the principles of personal data processing and the rights of data subjects, please check the Privacy Policy.

Discover More

Applicant Tracking System
11 Jun 2026
What is an ATS? The Ultimate Guide to Recruitment Software (2026)
Definition, history, features, AI, agents, and everything you need to know before choosing the ultimate ATS for HR, agencies, and contracting
Discover More

Recruitment Process
8 Jun 2026
CRM in a Recruitment Agency: Because Your Client is a Critical Part of the Hiring Process
CRM in a Recruitment Agency: Because Your Client is a Critical Part of the Hiring Process
Discover More

Recruitment Process
5 Jun 2026
The Project Is Closed. The Candidate Is Hired. But What Happens to the Other 136 People?
The Project Is Closed. The Candidate Is Hired. But What Happens to the Other 136 People?
Discover More
Applicant Tracking System
11 Jun 2026
What is an ATS? The Ultimate Guide to Recruitment Software (2026)
Definition, history, features, AI, agents, and everything you need to know before choosing the ultimate ATS for HR, agencies, and contracting
Discover More
Recruitment Process
8 Jun 2026
CRM in a Recruitment Agency: Because Your Client is a Critical Part of the Hiring Process
CRM in a Recruitment Agency: Because Your Client is a Critical Part of the Hiring Process
Discover More

